网站所有者一直无法确定 AI 服务如何使用他们的内容进行训练或其他用途。今天,Cloudflare 发布了一套工具,旨在帮助网站拥有者、创作者和出版商重新掌控他们的内容如何提供给与 AI 相关的机器人和爬虫。所有Cloudflare客户现在都可以审核和控制 AI 模型如何访问其站点上的内容。
首先是一个详细的分析视图,展示了爬取您网站的 AI 服务以及它们访问的具体内容。客户可以按 AI 提供商、机器人类型查看活动,以及网站的哪些部分最受欢迎。Cloudflare 上的每个站点都可以使用这些数据,并且不需要任何配置。
我们希望这种新级别的可见性能促使团队决定是否将内容暴露给 AI 爬虫。为了给他们提供做出决定的时间, Cloudflare 现已在我们的仪表板中提供了一键选项,用于立即阻止任何 AI 爬虫访问任何站点。团队可利用这个“暂停”来决定是否允许特定的 AI 提供商或哪些类型的机器人继续访问。一旦做出决定,管理员只需点击几下鼠标,就可以使用 Cloudflare 仪表板中的新过滤器实施这些策略。
一些客户已经决定直接与 AI 公司谈判以达成协议。这些合同中的很多含了关于扫描频率和可访问内容类型的条款。我们希望这些发布者拥有工具来衡量这些协议的实施情况。作为今天公告的一部分,Cloudflare 客户现在可以一键生成报告,用于审计这些协议中允许的活动。
我们还认为,任何规模的网站都应该能够决定,对于 AI 模型使用其内容,他们希望如何获得补偿。今天的公告预览一项新的 Cloudflare 变现功能,该功能将为网站拥有者提供就对其内容的扫描设置价格、控制访问和获取价值的工具。
问题是什么?
直到最近,互联网上的机器人和爬虫大致分为两类:好和坏。好的机器人,比如搜索引擎爬虫,帮助用户发现您的网站并为您带来流量。而坏的机器人会尝试破坏您的网站,抢在客户前面排队,或者抓取竞争数据。我们打造了 Cloudflare Bot Management 平台,让您能够区分这两大类机器人,并允许或阻止它们。
人工智能大型语言模型 (LLM) 和其他生成式工具的兴起创造了更加模糊的第三类。不同于恶意机器人,与这些平台相关的爬虫不会积极尝试使您的网站下线或妨碍您的客户。他们并不试图窃取敏感数据;只想浏览您网站上已经公开的内容。
然而,与有用的机器人不同,这些与 AI 相关的爬虫不一定会为您的网站带来流量。AI Data Scraper (人工智能数据抓取)机器人扫描您网站上的内容以训练新的 LLM。然后,您的内容会被放入一种混合器中与其他内容混合在一起,并用于回答用户问题,不会注明来源,也不需要用户访问您的网站。另一种爬虫是 AI Search Crawler (人工智能搜索爬虫)机器人,它们会扫描您的内容,并在响应用户的搜索时尝试进行引用。缺点是那些用户可能仅停留在该界面内,而不会访问您的网站,因为答案已经在他们面前的页面上汇总了。
这种模糊性让网站拥有者面临一个艰难的决定。价值交换不明确。而且网站拥有者在追赶的过程中处于劣势。许多网站允许这些 AI 爬虫扫描其内容,因为它们在大多数情况下看起来像“好”机器人——结果却导致他们的网站流量减少,因为他们的内容已被重新包装在 AI 生成的答案中。
我们认为这给开放的互联网构成了风险。如果无法控制扫描和实现价值,网站拥有者将缺乏启动或维护互联网资产的动力。创作者会把更多内容放在付费区,而最大的出版商会直接达成交易。反过来,AI 模型提供者将难以在较小的网站上找到和访问高质量的长尾内容。
双方都缺乏建立健康、透明的权限和价值交换的工具。从今天开始,Cloudflare 为网站拥有者提供他们开始解决这个问题所需的服务。如下详细列出我们建议所有客户遵循的一系列步骤。
第一步:了解 AI 模型如何使用您的站点
Cloudflare上的每个站点现在都可以访问一个新的分析视图,其中总结了流行和已知 AI 服务的爬取行为。您可以在仪表板中选择一个站点,然后导航到左侧导航栏的 AI Audit 选项卡以开始查看此信息,了解 AI 如何对您的内容进行扫描。
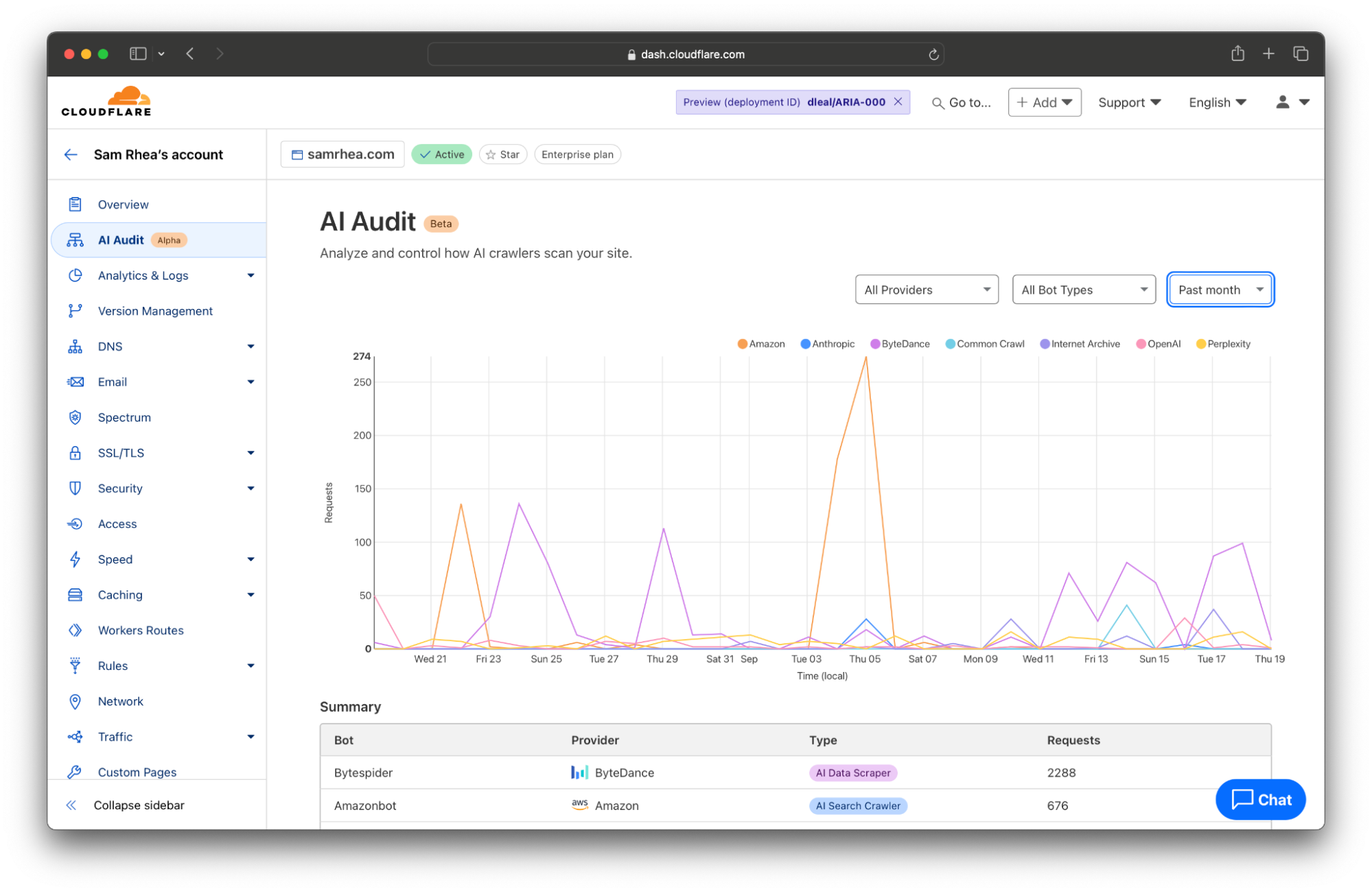
当 AI 模型提供者访问您网站上的内容时,它们会依靠称为“机器人”或“爬虫”的自动化工具来扫描页面。机器人将请求页面内容,捕获响应,将其存储为未来数据训练集的一部分,或者记住它以供未来的 AI 搜索引擎结果使用。
这些机器人常常通过在其请求中包含一个称为用户代理的 HTTP 标头来向您的站点(和 Cloudflare 的网络)表明它们自己的身份。但是在某些情况下,来自其中一个 AI 服务的机器人可能不会发送标头,因而 Cloudflare 会依赖其他启发式方法来识别它们,例如 IP 地址或行为。
当机器人表明身份时,标头将包含一串带有机器人名称的文本。例如, Anthropic 有时会使用名为 ClaudeBot 的机器人在互联网上爬取站点。当该服务从您在 Cloudflare 上的站点请求某个页面的内容时, Cloudflare 将用户代理记录为 ClaudeBot 。
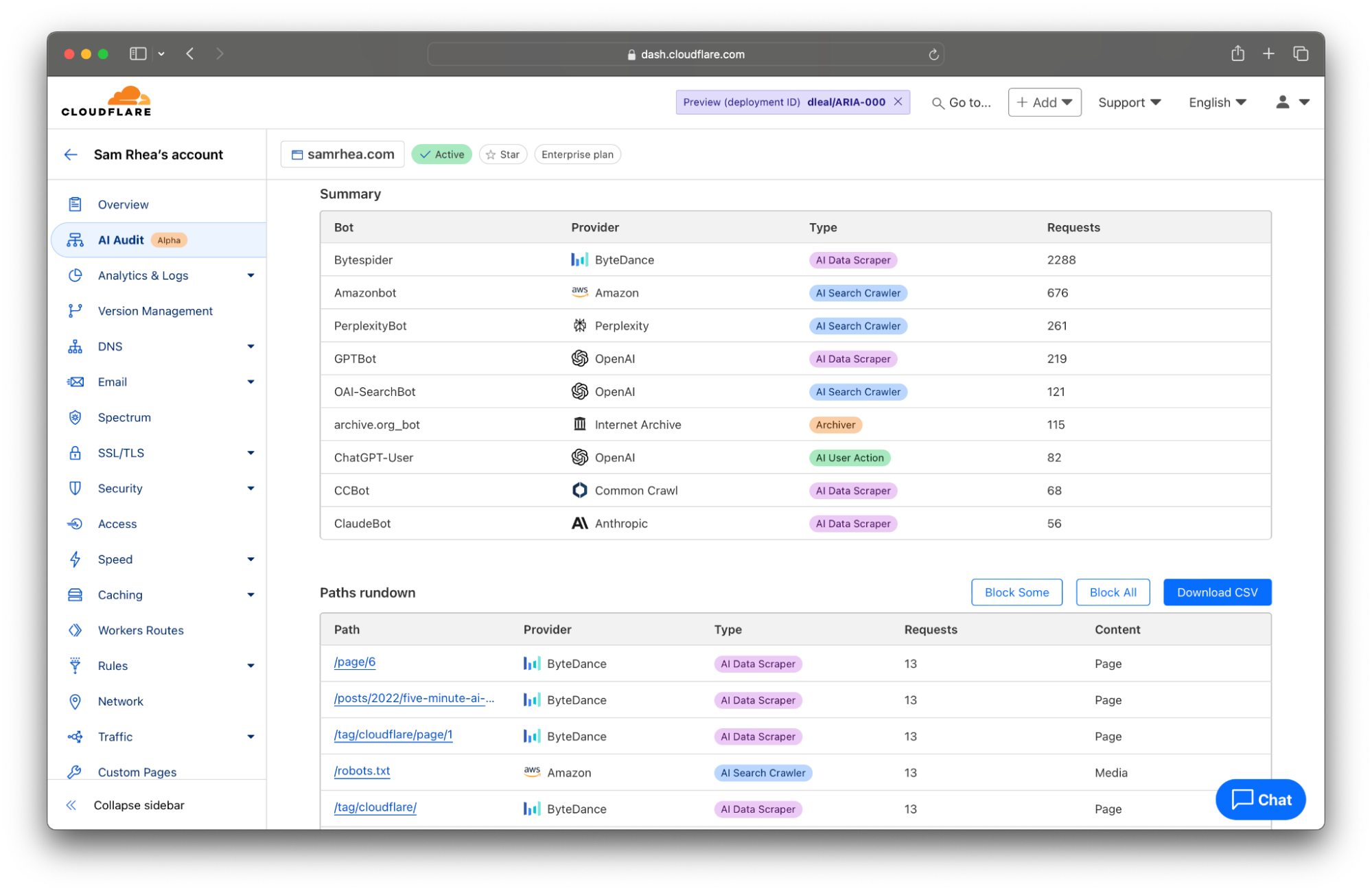
Cloudflare 会获取从网站访问中收集的日志,并查找与已知 AI 机器人和爬虫相匹配的用户代理。我们会汇总每个爬虫的活动,并为您提供过滤器,以查看仅来自特定 AI 平台的活动。许多 AI 公司使用多个爬虫来完成不同的任务。当 OpenAI 扫描站点以进行数据抓取时,它们依赖于 GPTBot,但在为其新的 AI 搜索引擎抓取站点时,则使用 OAI-SearchBot。
这些差异很重要。来自不同类型机器人的扫描可能会影响您网站的流量或内容的归属。作为响应的一部分,AI 搜索引擎通常会链接到网站,从而可能将访问者带到您的站点。在这种情况下,您可能希望这些类型的机器人对您的互联网资产进行爬取。另一方面,AI 数据抓取工具的存在就是为了尽可能多地阅读互联网上的信息,以训练未来的模型或改进现有的模型。
我们认为您应该知道机器人爬取您网站的原因、时间和频率。今天的发布提供一个过滤器,供您按 AI Data Scraper、AI Search Crawler 和 Archiver 等类别查看机器人活动。
利用这些数据,您可以开始分析 AI 模型如何访问您的网站。这些信息可能会让人感到不知所措,尤其是如果您的团队还没有时间决定如何处理 AI 对您的内容的扫描。如果您发现自己不确定如何回复,请继续进行第 2 步。
第二步:给自己暂停一下,决定下一步该做什么
我们与几家组织进行了交谈,他们知道自己的网站对 AI 爬虫来说是有价值的目的地,但还不知道该如何处理。这些团队需要“暂停”一下,以便就如何向这些服务提供他们的数据做出明智的决定。
Cloudflare 现在就为您提供了这样一个简单的按钮。使用任何计划的任何客户都可以选择阻止所有 AI 机器人和爬虫,以便在决定允许什么之前先暂停一下。
要启用该选项,请导航到 Cloudflare 仪表板“安全”选项卡下的“机器人”部分。点击右上角的蓝色链接,配置 Cloudflare 代理处理机器人流量的方式。接下来,将“阻止 AI Scrapers 和 Crawlers”卡片中的按钮切换到“开启”位置。
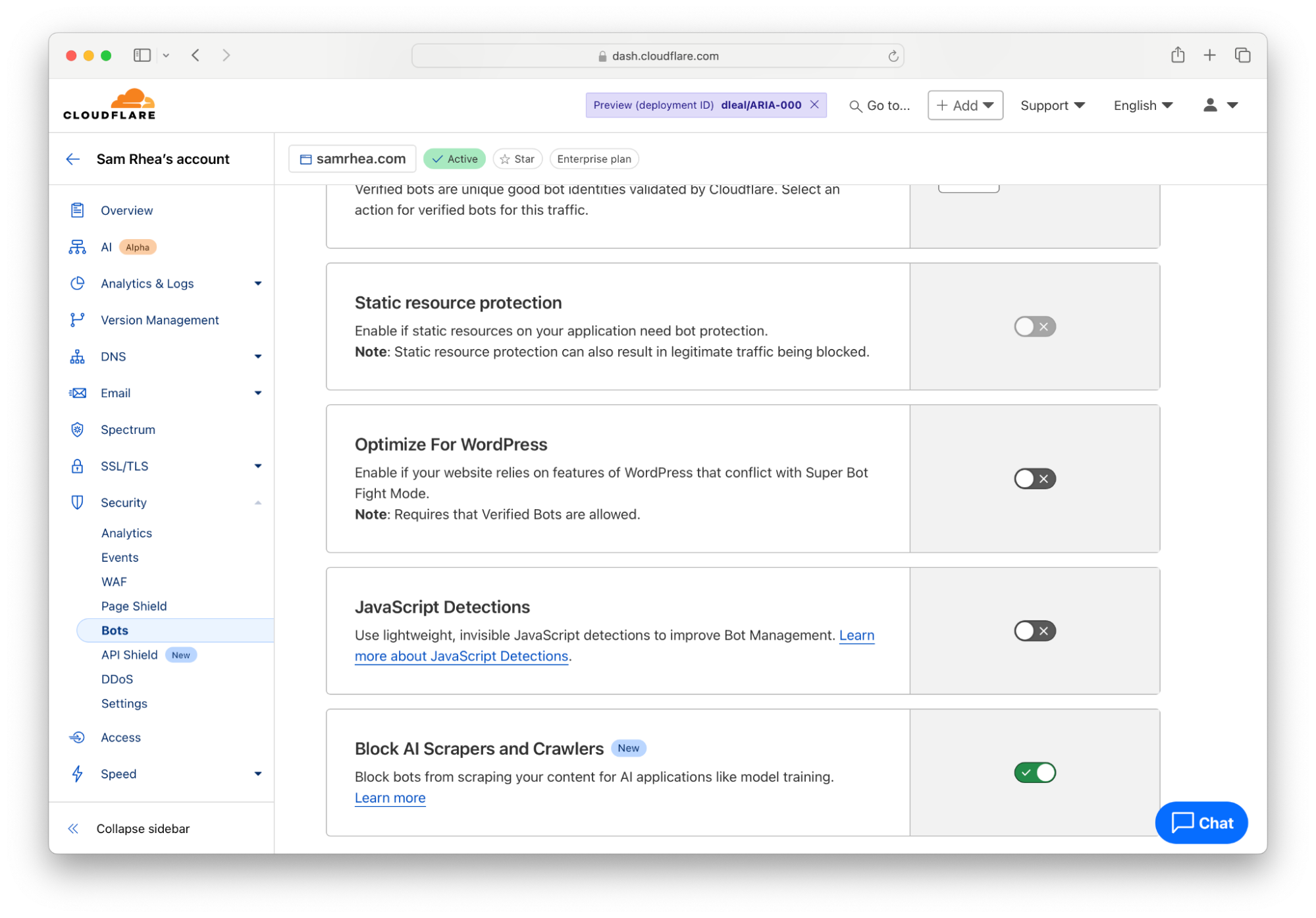
这个一键式选项会根据 Cloudflare 维护的列表阻止已知的 AI 相关机器人和爬虫访问您的网站。实施屏蔽后,您和您的团队可以更从容地决定接下来该如何处理您的内容。
第 3 步:控制要允许的机器人
暂停按钮为您的团队争取了时间,让您决定希望这些爬虫与您的内容之间建立什么样的关系。一旦您的团队做出决定,您就可以开始依靠 Cloudflare 的网络来实施该政策。
如果该决定是“我们不允许任何爬取”,那么您可以将上面提到的阻止按钮保持在“开启”状态。如果您想允许一些选择性的爬取,今天的更新为您提供了选项,以便允许某些类型的机器人或者仅允许来自特定提供商的机器人访问您的内容。
对于一些团队来说,决定可能是允许与 AI 搜索引擎相关的机器人扫描他们的互联网资产,因为这些工具仍然可以为网站带来流量。其他组织可能会与特定的模型提供商签订协议,他们希望允许来自该提供商的任何类型的机器人访问他们的内容。现在,客户可以导航到 Cloudflare 仪表板的 WAF 部分,实施这些类型的策略。
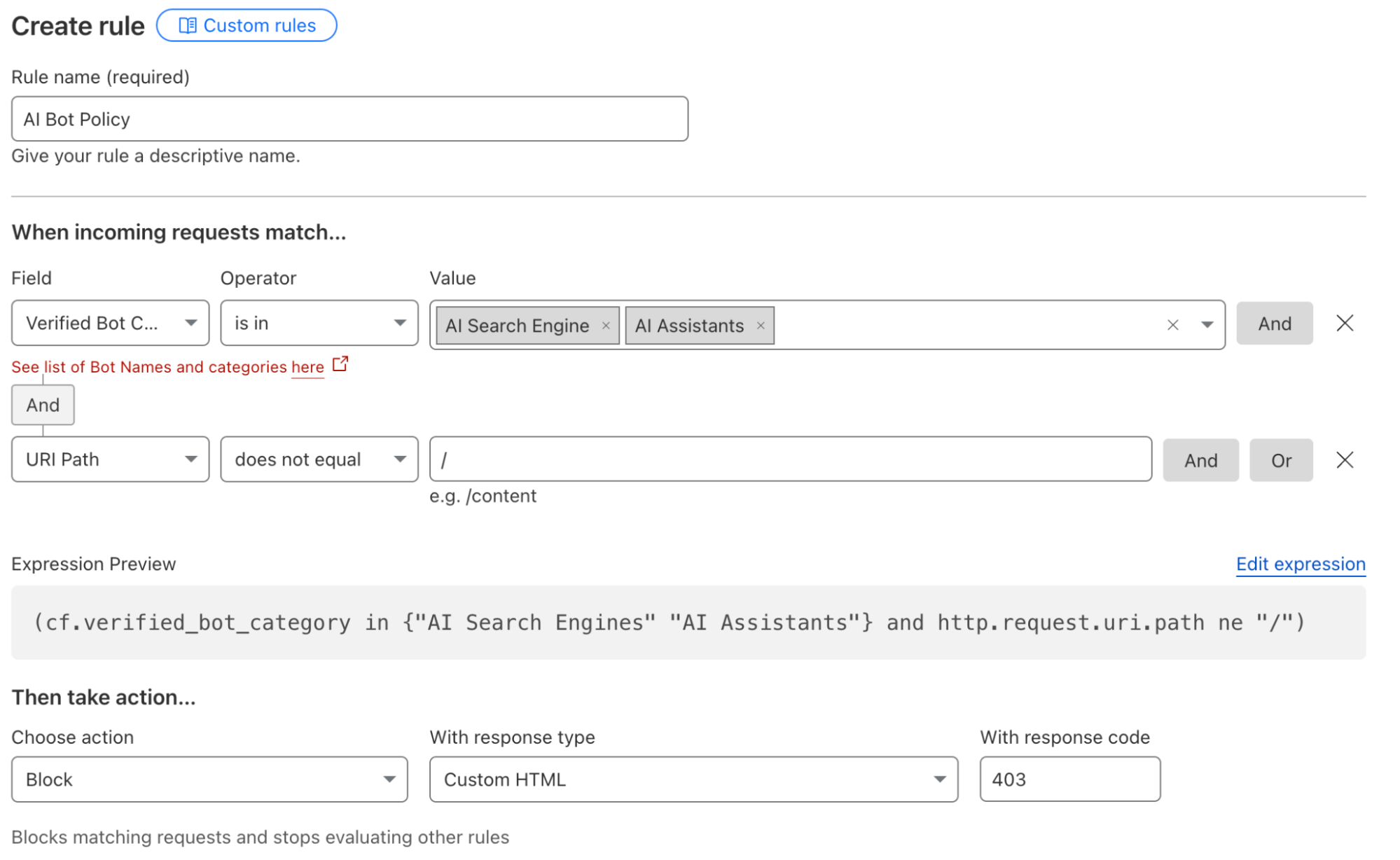
管理员还可以创建规则,例如,阻止所有 AI 机器人,但来自特定平台的机器人除外。如果团队对大多数 AI 平台持怀疑态度,但对某个 AI 模型提供商及其策略感到放心,则可以部署这些类型的过滤器。如果网站所有者已经签订合同以允许某个提供商进行扫描,这些类型的规则还可以用于执行合同。网站管理员需要创建一个规则,阻止所有类型的 AI 相关机器人,然后添加一个例外,允许来自其 AI 合作伙伴的特定机器人。
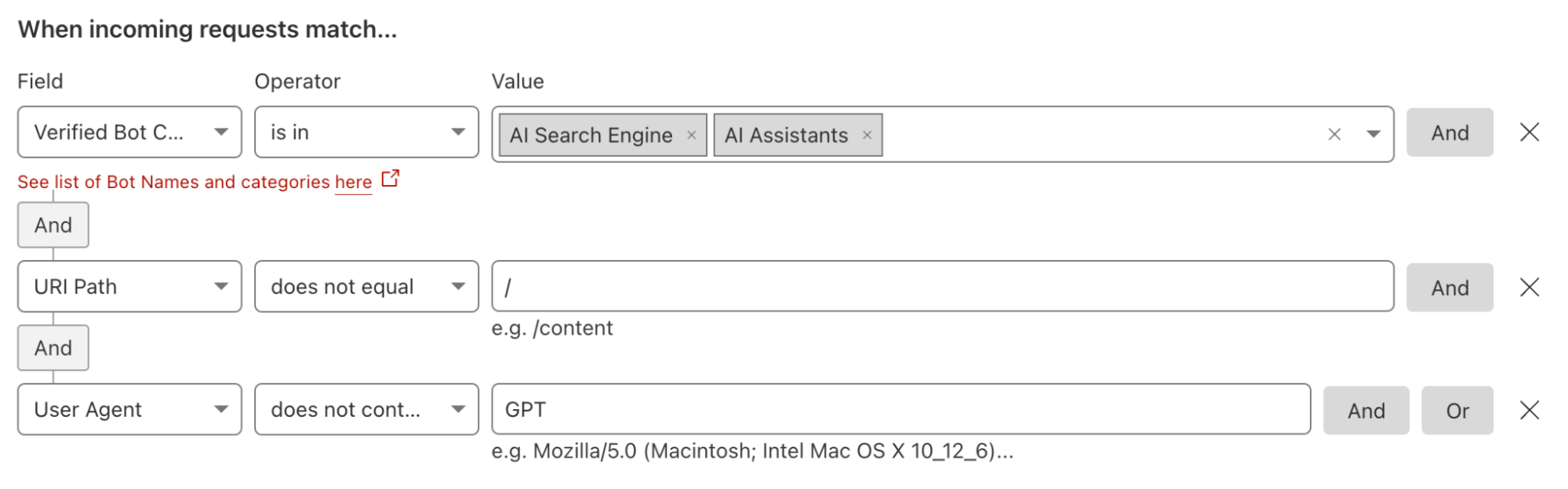
除了应用这些新的过滤器外,我们还建议客户考虑更新其服务条款以涵盖这一新用例。我们记录了我们建议 “好”机器人和爬虫对 robots.txt 文件采取的步骤。作为这些最佳实践的扩展,我们将在文档中添加一个新部分,提供一个示例服务条款部分,网站所有者可以考虑使用该部分来确定 AI 扫描需要遵循您在 robots.txt 文件中定义的政策。
第四步:审计现有扫描协议
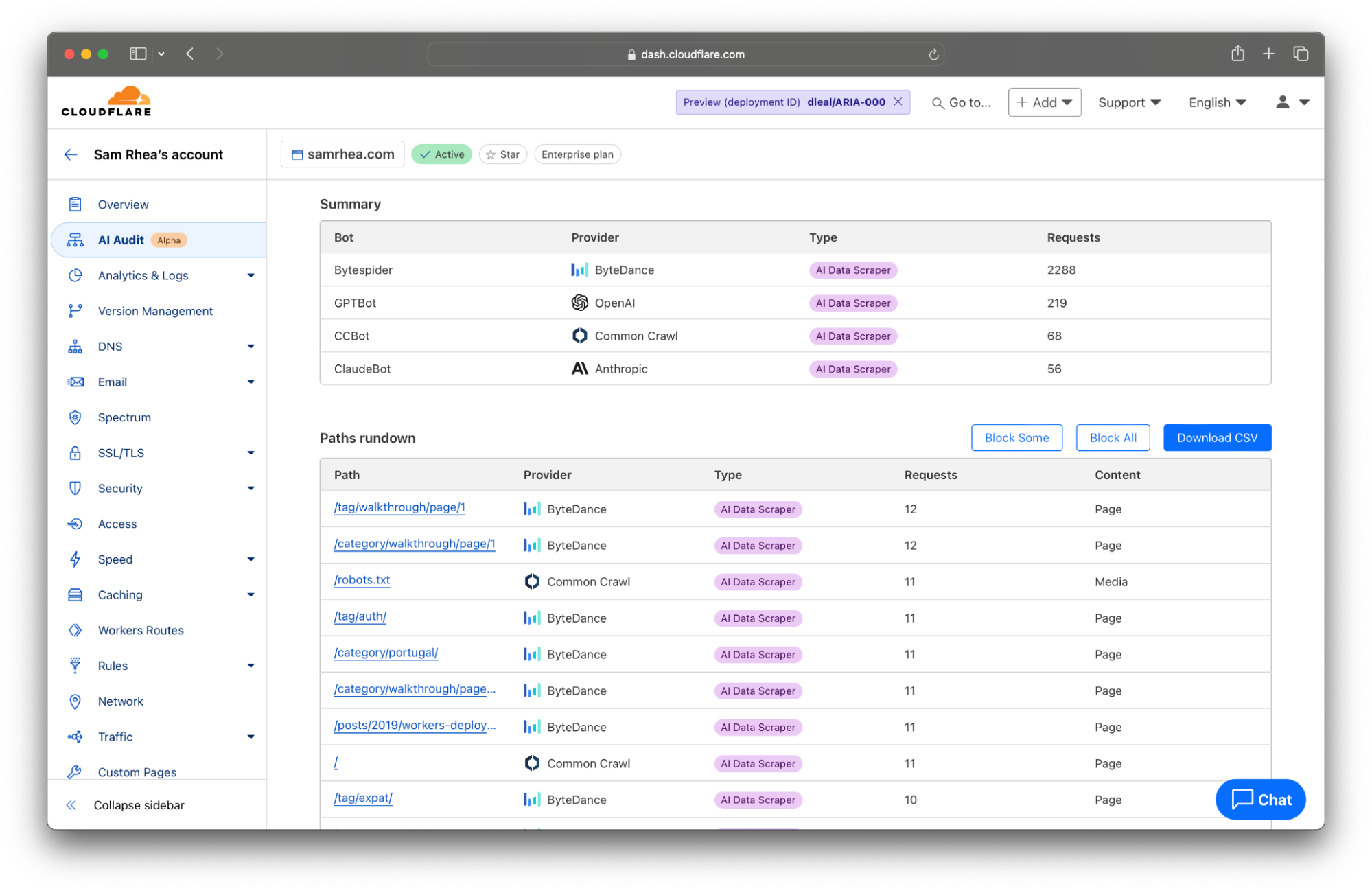
越来越多站点正直接与模型提供商签署协议,许可其内容的消费以换取报酬。其中许多交易都包含用于确定某些部分或整个网站爬取速度的条款。Cloudflare 的 AI Audit 选项卡为您提供了监控此类合同的工具。
现在,AI Audit 工具底部的表格会列出网站上最受欢迎的内容,其依据是在页面顶部所设过滤器中的时间段内的扫描次数。您可以点击“导出为 CSV ”按钮,快速下载一个文件,其中包含此处展示的详细信息,以便与您允许访问内容的 AI 平台讨论任何差异。
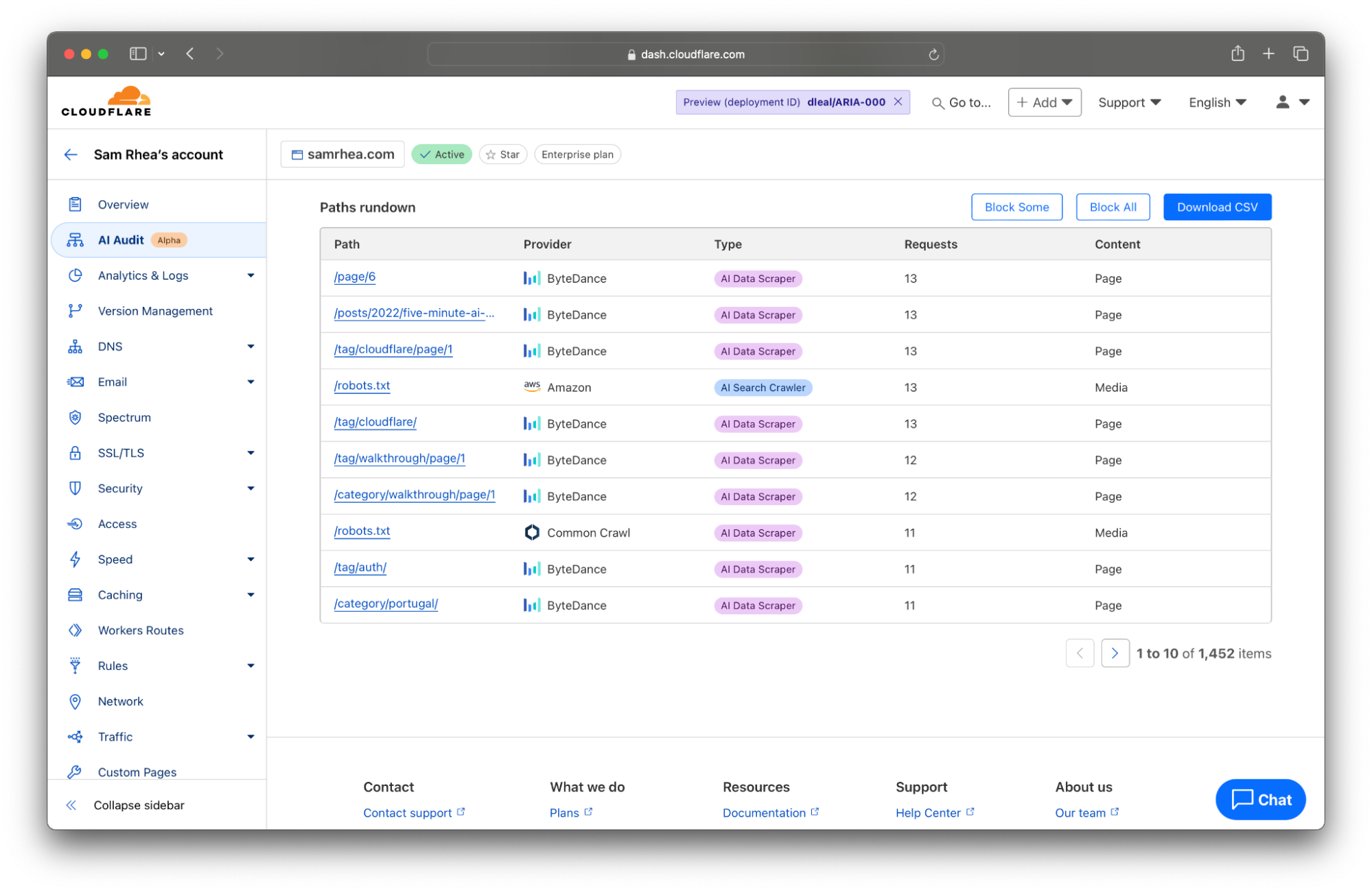
今天,向您提供的数据代表了我们从签订了此类协议的客户处听闻的关键指标:针对特定页面的请求,以及针对整个网站的请求。
第五步:准备您的站点,以便从 AI 扫描中获取价值
并非每个人都有时间或人脉与 AI 公司谈判协议。到目前为止,只有互联网上最大的出版商才有资源设定这种条款并为他们的内容获得报酬。
其他人在如何处理其数据方面只有两个基本选择:阻止所有扫描或允许无限制访问。今天的发布让内容创作者拥有比这两个选项更多的可见性和控制权,但互联网上的“长尾”站点依然缺乏变现的途径。
我们认为,任何规模的网站都应该就对其内容的使用获得公平的回报。Cloudflare 计划在我们的仪表板中推出一个新的组件,其功能将不仅仅是阻止和分析爬网行为。网站所有者将能够为其网站或网站的某些部分设定价格,然后根据设定的价格和模型提供商的扫描次数向模型提供商收费。我们将处理其余的工作,让您可以专注于为自己的受众创造精彩的内容。






